Agents Training Agents: A practical architecture for autonomous self-improvement
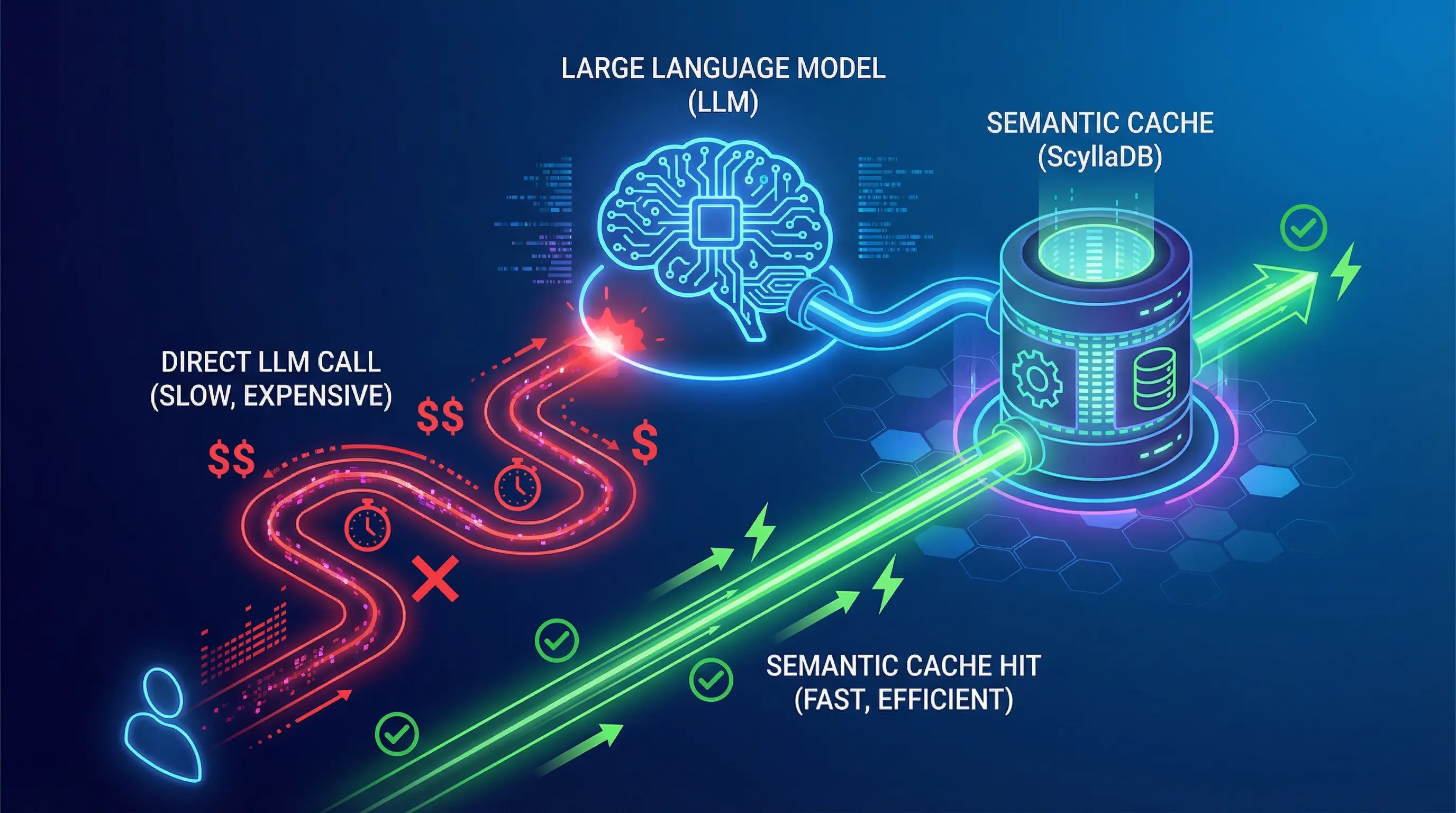
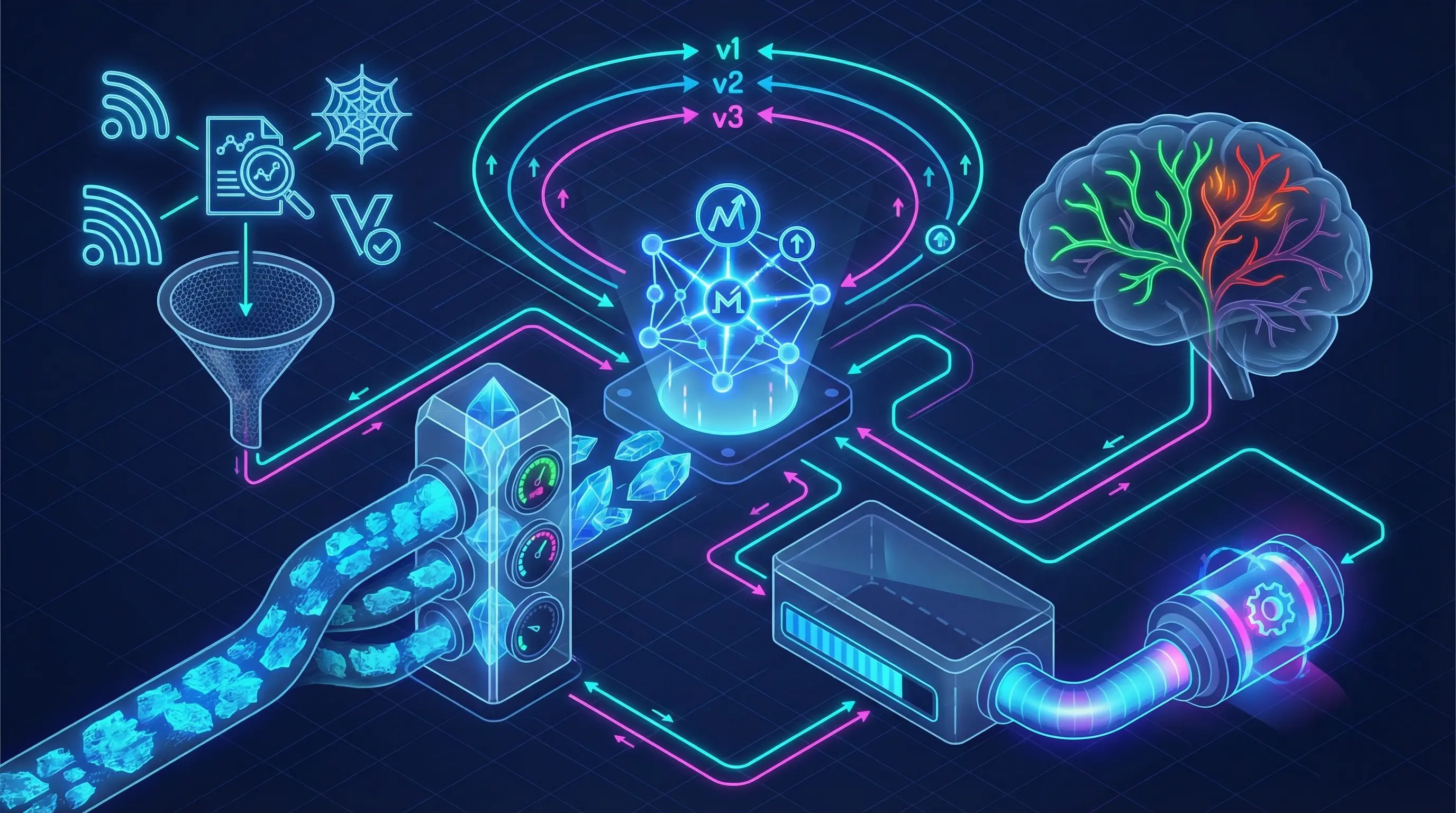
What if an AI agent could look at a piece of content and think, “Huh, I don’t know much about this”—and then do something about it? Not just flag it for a human. Actually go out, find relevant data, validate it, verify it, and eventually use it to improve itself. This isn’t science fiction. It’s a practical architecture I’ve been thinking about, and I want to walk you through it. ...